My old web server has been retired. I have been moving sites the last couple of days to a new box. I took the time to virtualize the machine and set everything up properly. The old box was starting to show it’s age with lots of modified configuration files and outdated software. The website seems to be loading significantly faster now too.
Monitoring Online ASM Datafile Moves
I’m moving a ~7TB database online as the development group that uses it doesn’t want to take any down time. Thankfully the database isn’t horribly active right now so moving the data files online isn’t causing a huge problem. The only other times I have moved data files online was in an incredibly busy database and it could take half a day per data file.
I don’t want them to continually bother me so I gave them a view that they could monitor the process through. Here are the caveat, I know when the move started, that is hard coded, also my volume names are easy to tell if they are on flash storage or spinning media as they are two different asm pools, so extracting the second character of the file name yields a ‘D’ or an ‘F’ where D is spinning media and F is flash media.
create or replace view storage_migration_status
'D', 'Spinning Media',
'F', 'Flash Media')
AS Metric,
TO_CHAR (ROUND (SUM (bytes) / 1024 / 1024 / 1024, 0) || ' GB')
AS VALUE
FROM v$datafile
GROUP BY SUBSTR (name, 2, 1)
UNION ALL
SELECT 'Average Transfer Speed'
AS metric,
TO_CHAR (
ROUND (
SUM (bytes / 1024 / 1024 / 1024)
/ ( 24
* ( SYSDATE
- TO_DATE ('2019/01/04 10:30', 'yy/mm/dd HH:MI'))),
0)
|| ' GB/hr')
AS VALUE
FROM v$datafile
WHERE SUBSTR (name, 2, 1) = 'F'
UNION ALL
SELECT 'Estimated time remaining'
AS metric,
TO_CHAR (
ROUND (
SUM (bytes / 1024 / 1024 / 1024)
/ ( SUM (bytes / 1024 / 1024 / 1024)
/ ( 24
* ( SYSDATE
- TO_DATE ('2019/01/04 9:00', 'yy/mm/dd HH:MI')))),
2)
|| ' Days')
AS VALUE
FROM v$datafile
WHERE SUBSTR (name, 2, 1) = 'D'NION ALL
SELECT 'Average Transfer Speed'
AS metric,
TO_CHAR (
ROUND (
SUM (bytes / 1024 / 1024 / 1024)
/ ( 24
* ( SYSDATE
- TO_DATE ('2019/01/04 10:30', 'yy/mm/dd HH:MI'))),
0)
|| ' GB/hr')
AS VALUE
FROM v$datafile
WHERE SUBSTR (name, 2, 1) = 'F'
UNION ALL
SELECT 'Estimated time remaining'
AS metric,
TO_CHAR (
SUM (bytes / 1024 / 1024 / 1024)
/ (ROUND (
SUM (bytes / 1024 / 1024 / 1024)
/ ( 24
* ( SYSDATE
- TO_DATE ('2019/01/04 9:00', 'yy/mm/dd HH:MI'))),
0))
|| ' Days')
AS VALUE
FROM v$datafile
WHERE SUBSTR (name, 2, 1) = 'D'
/Then they can check on the stats for themselves
SYS oradb1> select * from storage_migration_status;
METRIC VALUE
------------------------ ----------------------------------------------
Spinning Media 6451 GB
Flash Media 128 GB
Average Transfer Speed 99 GB/hr
Estimated time remaining 2.8 DaysIt’s not pretty but it gets the job done, leaving me with less contact with people, which is great 🙂
Reporting Database Sizes
I frequently need to pull size information about a large number of databases. OEM has an interesting capacity planning feature, but some times I just want the raw data. This is the base query I start with and add on additional information or slice it in different ways to fit what I need. I run this in the OEM repository.
col target_name for 130
SELECT target_name, SUM (maximum)
FROM sysman.mgmt$metric_daily t
WHERE target_type IN ('oracle_database', 'rac_database')
AND metric_column IN ('spaceAllocated')
AND TRUNC (rollup_timestamp) = TRUNC (SYSDATE) - 1
AND UPPER (target_name) LIKE '%&1%'
GROUP BY target_name
ORDER BY target_name
This gives you the size, by database as of the previous day.
ORA 600 [kcbAdoptBuffers_pw]
We hit this bug the other day. The oracle note references creating an index as part of this bug. As far as I can tell, we weren’t doing that when we hit this. It is a vendor application though, and I know they do some DDL such as creating tables on the fly. I was never able to reproduce the bug at will, but I was getting flooded with these alerts.
Oracle support recommended we change the _db_cache_pre_warm parameter to false
SELECT ksppinm, ksppstvl, ksppdesc FROM x$ksppi x, x$ksppcv y WHERE x.indx = y.indx AND translate (ksppinm, '_', '#') like '#%' AND ksppinm = '_db_cache_pre_warm'; KSPPINM KSPPSTVL KSPPDESC -------------------------- ---------- ------------------------------------------------------------ _db_cache_pre_warm TRUE Buffer Cache Pre-Warm Enabled : hidden parameter
We changed it to false, and did a rolling restart of the database
alter system set "_db_cache_pre_warm " = FALSE scope=spfile;
after restarting
SELECT ksppinm, ksppstvl, ksppdesc FROM x$ksppi x, x$ksppcv y WHERE x.indx = y.indx AND translate (ksppinm, '_', '#') like '#%' AND ksppinm = '_db_cache_pre_warm'; KSPPINM KSPPSTVL KSPPDESC -------------------------- ---------- ------------------------------------------------------------ _db_cache_pre_warm FALSE Buffer Cache Pre-Warm Enabled : hidden parameter
The errors have stopped. This appears to be bug 21864012
Setting up SSL ACL in 12cR2
Before you can connect to a website you need to setup the oracle wallet. Start by going to the website you are going to be connecting to. In this case I am just using my own site. I am also using Safari on OSX, the steps differ slightly depending on operating system and browser.
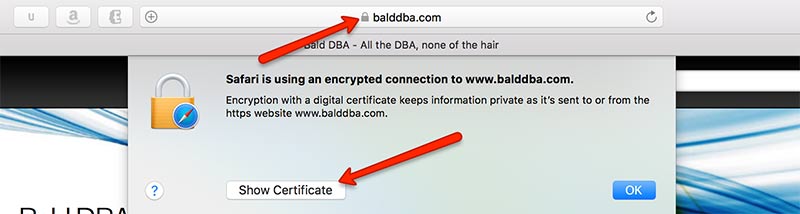
After clicking the padlock icon, and show certificate, we represented with the certificate chain. The root certificate is trusted by the browser, which then is used to validate the intermediary certificate which belongs to the encryption authority, in this case it’s Let’s Encrypt. Lets Encrypt in turn validates the certificate for my site. When oracle tries to connect to balddba.com it will need the intermediary and the root certificate to validate the server we are connecting to.
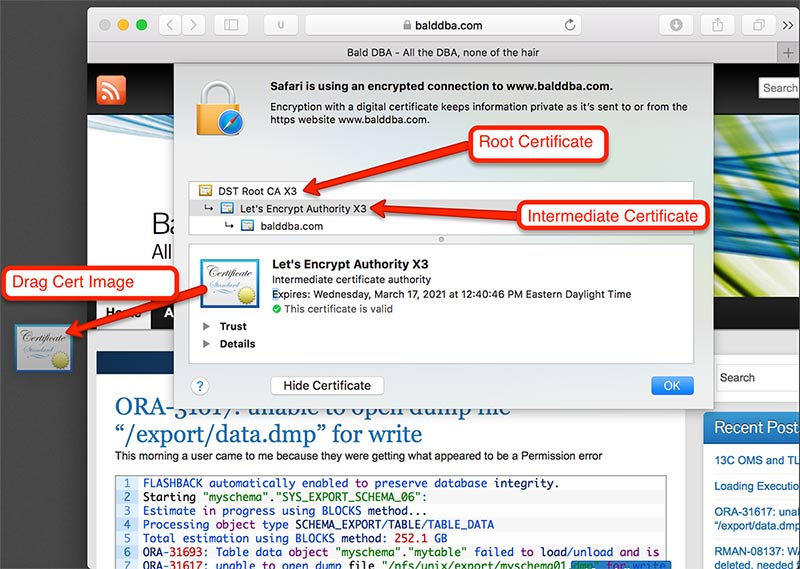
When I download the certificate we need to convert it to base-64 encoding so that we can handle it like a text file.
Convert the certificates to base-64
amyers$ openssl x509 -inform DER -in root.cer > root.crt amyers$ openssl x509 -inform DER -in intermediate.cer > intermediate.crt
On the database server, create a folder to hold the wallet. Since I am doing this on the oracle cloud, and I only have one database SID, and the database is not RAC, I am not worrying about putting the wallet into a dynamic location. If you want to have a wallet per sid, you can use the $QNAME variable in the sqlnet.ora
[oracle@testdb db_wallet]$ pwd /u01/app/oracle/admin/ORCL/db_wallet [oracle@testdb db_wallet]$ ls -tlr total 0
Modify the sqlnet.ora to point to the new wallet directory
WALLET_LOCATION = (SOURCE=(METHOD=FILE)(METHOD_DATA=(DIRECTORY=/u01/app/oracle/admin/ORCL/db_wallet)))
Create a new auto login wallet using orapki
orapki wallet create -wallet /u01/app/oracle/admin/ORCL/db_wallet -pwd WallPass2 -auto_login
Add the root and intermediate certificates to the wallet
[oracle@testdb certs]$ cd /home/oracle/certs [oracle@testdb certs]$ ls -tlr total 8 -rw-r--r-- 1 oracle oinstall 1200 Dec 4 16:53 root.crt -rw-r--r-- 1 oracle oinstall 1648 Dec 4 16:53 intermediate.crt [oracle@testdb certs]$ orapki wallet add -wallet /u01/app/oracle/admin/ORCL/db_wallet -trusted_cert -cert "/home/oracle/certs/root.crt" -pwd WallPass2 Oracle PKI Tool : Version 12.2.0.1.0 Copyright (c) 2004, 2016, Oracle and/or its affiliates. All rights reserved. Operation is successfully completed. [oracle@testdb certs]$ orapki wallet add -wallet /u01/app/oracle/admin/ORCL/db_wallet -trusted_cert -cert "/home/oracle/certs/intermediate.crt" -pwd WallPass2 Oracle PKI Tool : Version 12.2.0.1.0 Copyright (c) 2004, 2016, Oracle and/or its affiliates. All rights reserved. Operation is successfully completed.
Then validate the certificates are in the wallet
[oracle@testdb db_wallet]$ orapki wallet display -wallet /u01/app/oracle/admin/ORCL/db_wallet Oracle PKI Tool : Version 12.2.0.1.0 Copyright (c) 2004, 2016, Oracle and/or its affiliates. All rights reserved. Requested Certificates: User Certificates: Trusted Certificates: Subject: CN=Let's Encrypt Authority X3,O=Let's Encrypt,C=US Subject: CN=DST Root CA X3,O=Digital Signature Trust Co.
Now that the wallet is setup with our certificates,
I am starting off by creating myself a new user, so that I am starting from scratch and not using the dba privileges.
SQL> create user amyers identified by MyPassword 2 default tablespace users 3 temporary tablespace temp 4 / User created.
Give the user access to connect and to use the url_http package
SQL> grant connect to amyers; Grant succeeded. SQL> grant resource to amyers; Grant succeeded. SQL> grant execute on utl_http to amyers; Grant succeeded.
We create a new ACL for the host, and for the wallet
begin
DBMS_NETWORK_ACL_ADMIN.APPEND_HOST_ACE(
host => 'www.balddba.com',
ace => xs$ace_type(privilege_list => xs$name_list('connect', 'resolve'),principal_name => 'AMYERS',principal_type => xs_acl.ptype_db));
end;
/
begin
dbms_network_acl_admin.append_wallet_ace(
wallet_path => 'file:/u01/app/oracle/admin/ORCL/db_wallet',
ace => xs$ace_type(privilege_list => xs$name_list('use_client_certificates'),principal_name => 'AMYERS',principal_type => xs_acl.ptype_db));
end;
/
Now we can test the connection
SQL> select utl_http.request('https://www.balddba.com',null,'file:/u01/app/oracle/admin/ORCL/db_wallet','WallPass2','balddba.com') from dual;
UTL_HTTP.REQUEST('HTTPS://WWW.BALDDBA.COM',NULL,'FILE:/U01/APP/ORACLE/ADMIN/ORCL
--------------------------------------------------------------------------------
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/x
{more html output}
There is something I think should be pointed out, there is a change from 12.1 to 12.2. utl_http.request takes in a new argument called https_host.
I was getting the following error
SQL> select utl_http.request('https://www.balddba.com',null,'file:/u01/app/oracle/admin/ORCL/db_wallet','WallPass2') from dual;
select utl_http.request('https://www.balddba.com',null,'file:/u01/app/oracle/admin/ORCL/db_wallet','WallPass2') from dual
*
ERROR at line 1:
ORA-29273: HTTP request failed
ORA-06512: at "SYS.UTL_HTTP", line 1501
ORA-24263: Certificate of the remote server does not match the target address.
ORA-06512: at "SYS.UTL_HTTP", line 380
ORA-06512: at "SYS.UTL_HTTP", line 1441
ORA-06512: at line 1
There is now another parameter that needs to be set, the https_host has to match the common name in the certificate.
LEN BINARY_INTEGER IN DEFAULT FUNCTION REQUEST RETURNS VARCHAR2 Argument Name Type In/Out Default? ------------------------------ ----------------------- ------ -------- URL VARCHAR2 IN PROXY VARCHAR2 IN DEFAULT WALLET_PATH VARCHAR2 IN DEFAULT WALLET_PASSWORD VARCHAR2 IN DEFAULT HTTPS_HOST VARCHAR2 IN DEFAULT
Here is my certificate
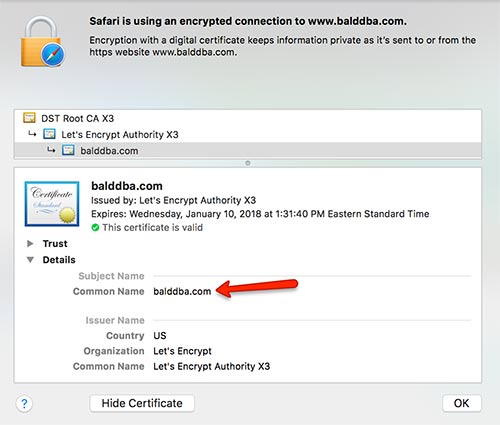
So after adding the arguemnt I am able to get to the page
SQL> select utl_http.request('https://www.balddba.com',null,'file:/u01/app/oracle/admin/ORCL/db_wallet','WallPass2','balddba.com') from dual;
UTL_HTTP.REQUEST('HTTPS://WWW.BALDDBA.COM',NULL,'FILE:/U01/APP/ORACLE/ADMIN/ORCL
--------------------------------------------------------------------------------
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/x
html1/DTD/xhtml1-strict.dtd">
13C OMS and TLSv1.2
A while ago I deployed OEM 13c to manage and monitor our databases. We have a lot of different systems on different architectures and operating systems. For the most part the move from OEM12c to OEM 13c was pretty smooth. As part of this process we were instructed to lock everything down to TLSv1.2, which is a huge pain inside of OEM. All the internal connections from the different components and nothing was listed in the documentation together. It took a lot of trial and error, but once it was setup, the deployment of the agents went just fine.
At least until I got to our AIX hosts. This is one of the longest open tickets I have ever had with oracle. Bug:23708579. After 9 months Oracle finally got me a patch that resolved the problem this week.
$ ./emctl start agent Oracle Enterprise Manager Cloud Control 13c Release 2 Copyright (c) 1996, 2016 Oracle Corporation. All rights reserved. Starting agent ................ failed. SSL Configuration failed at Startup Consult emctl.log and emagent.nohup in: /u01/app/oracle/product/agent13c/agent_inst/sysman/log
From the log files
27656382 :: 2017-04-11 11:49:08,943::AgentLifeCycle.pm: Processing setproperty agent 27656382 :: 2017-04-11 11:49:08,943::AgentStatus.pm:Processing setproperty agent 27656382 :: 2017-04-11 11:49:12,411::AgentStatus.pm:/u01/app/oracle/product/agent13c/agent_13.2.0.0.0/bin/emdctl setproperty agent -name SSLCipherSuites -value TLS_RSA_WITH_AES_128_CBC_SHA returned 0 27656382 :: 2017-04-11 11:49:12,412::Cleaning up agent command lock 27656382 :: 2017-04-11 11:49:12,412::AgentCommandLock:closed file handle of emctl lockfile 25624672 :: 2017-04-11 11:49:23,995::Initializing the agent command locking system 25624672 :: 2017-04-11 11:49:24,039::AgentLifeCycle.pm: Processing stop agent 25624672 :: 2017-04-11 11:49:24,039::AgentLifeCycle.pm: ParentProcess id=9175258 25624672 :: 2017-04-11 11:49:26,815::AgentStatus.pm:emdctl status agent returned 1 25624672 :: 2017-04-11 11:49:26,815::Status Output:Status agent Failure:Unable to connect to the agent at https://myoemserver:3872/emd/lifecycle/main/ [Connection refused]
There was a lot of confusion over this issue and originally they told me it was a bug in AIX that we would need to get IBM to fix. It turns out the patch that was needed was an agent patch
After applying patch: 25237184 the agent can now be locked to TLSv1.2 by adding the following to emd.properties
_frameworkTlsProtocols=TLSv1.2 _frameworkSSLContextProtocol=TLSv1.2
and then by re-securing the agent with the “-protocol tlsv1.2” flag
./emctl secure agent "myPassword" -protocol tlsv1.2
After this the agent was able to start up and start communicating with the OMS.
Loading Execution Plan for AWR
Create a new tuning set
BEGIN DBMS_SQLTUNE.CREATE_SQLSET(sqlset_name => '0uff0s72zg781_tuning_task10'); END; /
Load the execution plan into the tuning set
DECLARE
cur sys_refcursor;
BEGIN
open cur for
select value(p) from table(dbms_sqltune.select_workload_repository(
begin_snap => 77002,
end_snap => 77003,
basic_filter => 'sql_id IN (''0uff0s72zg781'') AND plan_hash_value = ''2294492662''')) p;
dbms_sqltune.load_sqlset('0uff0s72zg781_tuning_task10', cur);
close cur;
END;
/
Apply the plan to the statement
DECLARE
my_plans PLS_INTEGER;
BEGIN
my_plans := DBMS_SPM.LOAD_PLANS_FROM_SQLSET(
sqlset_name => '0uff0s72zg781_tuning_task10',
fixed => 'YES');
END;
/
ORA-31617: unable to open dump file “/export/data.dmp” for write
This morning a user came to me because they were getting what appeared to be a Permission error
FLASHBACK automatically enabled to preserve database integrity. Starting "myschema"."SYS_EXPORT_SCHEMA_06": Estimate in progress using BLOCKS method... Processing object type SCHEMA_EXPORT/TABLE/TABLE_DATA Total estimation using BLOCKS method: 252.1 GB ORA-31693: Table data object "myschema"."mytable" failed to load/unload and is being skipped due to error: ORA-31617: unable to open dump file "/nfs/unix/export/myschema01.dmp" for write ORA-19505: failed to identify file "/nfs/unix/export/myschema01.dmp" ORA-17503: ksfdopn:4 Failed to open file /nfs/unix/export/msychema01 ORA-17500: ODM err:File does not exist
I checked the directory listed, /nfs/unix/export. It is mounted on both nodes of the cluster.
Checked file permissions, using touch I created a file as the oracle user, and deleted it, no permissions issues there.
It turns out it was the directory object itself! I looked at the job definition, and it was using the directory /export
Export is a link to the /nfs/unix/export directory. The second node had link, but not the first! What threw me off was the directory object itself was only pointing to /export, but the error message was pointing to the full NFS path. Dropping and re-creating the directory object in the database pointing to /nfs/unix/export/ resolve the issue.
RMAN-08137: WARNING: archived log not deleted, needed for standby or upstream capture process
On a non-production database I was getting the following error when trying to delete archive logs with RMAN.
RMAN-08137: WARNING: archived log not deleted, needed for standby or upstream capture process archived log file name=+RECO/DBP1/ARCHIVELOG/2017_05_07/thread_1_seq_32041.11548.943352263 thread=1 sequence=32041
This database does not have any golden gate processes associated with it, so why doesn’t Oracle want to delete the archive log?
The database was rebuilt with a copy of a production database that did have golden gate running on it.
We can see the name of the extract that is still registered with the database.
SYS dbp01> select CAPTURE_NAME from dba_capture; CAPTURE_NAME -------------------------------------------------------------------------------------------------------------------------------- OGG$CAP_EXTDBP01 Elapsed: 00:00:00.35
Since the database was a copy of our production database that did have golden gate running, it till thinks there is a valid extract. Connecting to the database and unregistered the extract allows the archive log to be deleted.
GGSCI (dclxoradbd01) 1> dblogin userid ggs, password xxxx Successfully logged into database. GGSCI (dclxoradbd01 as ggs@dp5fact1) 9> UNREGISTER EXTRACT EXTFWBP database Successfully unregistered EXTRACT EXTFWBP from database.
UPDATE 11/13/2017:
One additional helpful command if you don’t have goldengate installed on the host where you are getting this error, you can remove the extract directly from the database
SQL> exec DBMS_CAPTURE_ADM.DROP_CAPTURE('OGG$CAP_EXTDBP01')
PL/SQL procedure successfully completed.
Update 08/10/2018
I usually just generate the code I need to run like this since I usually want to drop all the captures
select 'exec DBMS_CAPTURE_ADM.DROP_CAPTURE('''||CAPTURE_NAME||''');' from dba_capture;
ORA-02396: exceeded maximum idle time, please connect again
I was doing a schema import last night, over a database link. Lack of sleep had set in and I was getting the following error
Processing object type SCHEMA_EXPORT/TABLE/INDEX/INDEX ORA-39126: Worker unexpected fatal error in KUPW$WORKER.FETCH_XML_OBJECTS [INDEX:"SCHEMA_OWNER"."TABLE2"] ORA-02396: exceeded maximum idle time, please connect again ORA-06512: at "SYS.DBMS_SYS_ERROR", line 95 ORA-06512: at "SYS.KUPW$WORKER", line 11259 ----- PL/SQL Call Stack ----- object line object handle number name 0x2156ad620 27116 package body SYS.KUPW$WORKER 0x2156ad620 11286 package body SYS.KUPW$WORKER 0x2156ad620 13515 package body SYS.KUPW$WORKER 0x2156ad620 3173 package body SYS.KUPW$WORKER 0x2156ad620 12035 package body SYS.KUPW$WORKER 0x2156ad620 2081 package body SYS.KUPW$WORKER 0x20d5f9bb0 2 anonymous block KUPP$PROC.CHANGE_USER KUPP$PROC.CHANGE_USER NONE connected to AAR00287 DBMS_LOB.TRIM DBMS_LOB.TRIM DBMS_LOB.TRIM DBMS_LOB.TRIM DBMS_METADATA.FETCH_XML_CLOB DBMS_METADATA.FETCH_XML_CLOB In procedure DETERMINE_FATAL_ERROR with ORA-02396: exceeded maximum idle time, please connect again
Now if you aren’t tired this should be a pretty obvious fix, the idle_time value on the remote server was set to 60 and was disconnecting me during the index build section of the import. I altered the profile to give my user/profile unlimited idle_time. Problem solve, import complete.